



【TypeScript】Result型でtry-catchを型安全に扱う


TypeScriptのResult型を使うと、try-catchでは型に表れなかった「失敗の可能性」をコンパイラに見せられます。catchの引数がunknownで扱いにくい、関数の型を見ても失敗するかどうか分からない、そんなもやもやの正体に心当たりがあるなら、この記事がそのまま処方箋になります。



Result型は、失敗を例外として投げる代わりに「成功か失敗かを表す値」として返す発想です。失敗が戻り値の型に乗るので、呼び出し側はコンパイラに「失敗を処理しろ」と促されます。Result型の原理、自前実装、neverthrowを使った実務的な書き方、導入範囲の判断軸をまとめて押さえます。
この記事は次のような方におすすめです。
- try-catchのcatchが
unknownになって扱いづらいと感じている方 - 関数のシグネチャに失敗の可能性が出ないことに不安がある方
- 自前のResult型とneverthrowの違い・使い分けを知りたい方
- Result型を導入すべきか、どこまで使うべきか判断したい方
読み終えるころには、失敗を型で表現する書き方が手に馴染み、目の前のコードでResult型を使うべきか、try-catchのままで十分かを自分で判断できるようになります。
それでは、順を追って詳しく見ていきましょう!
- 未経験で後悔したくない
【実体験】未経験からITエンジニアに転職して後悔した話|4社経験してわかった「最初の選択ミス」 - 年収が低くて不安
エンジニア転職体験談|4社で年収250→510万にした全記録
Result型が必要になる型安全上の課題
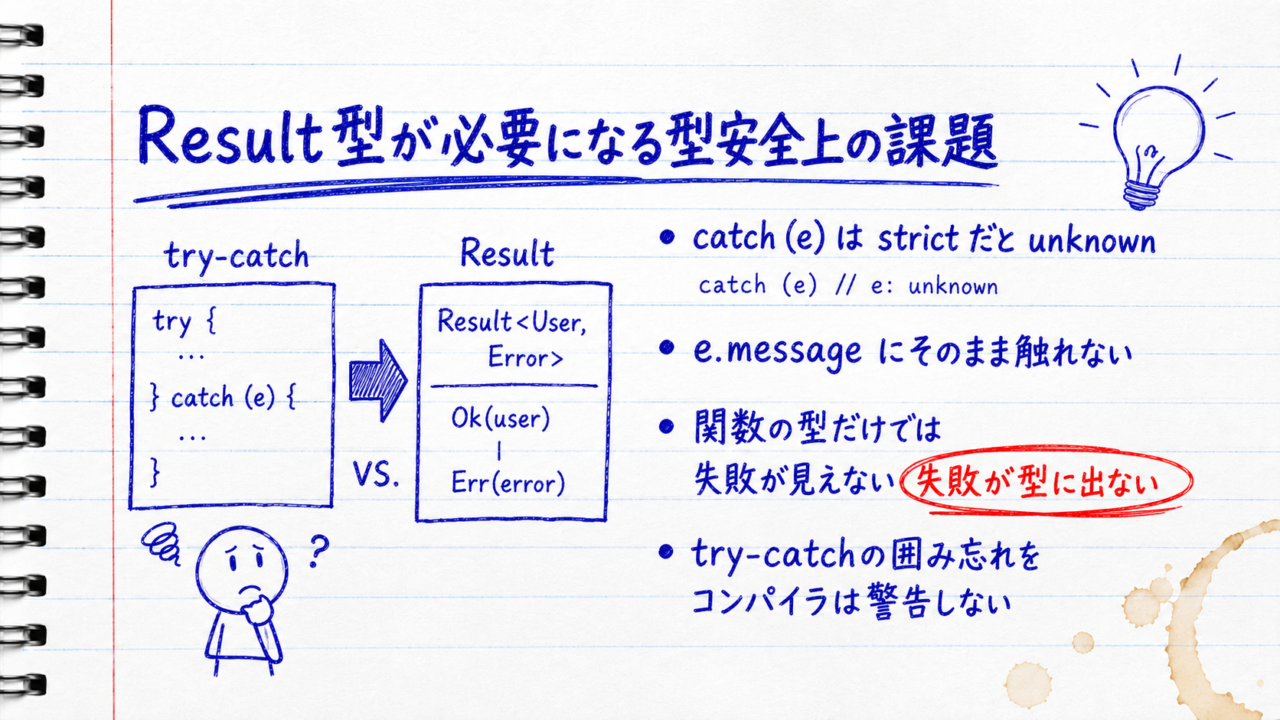
try-catchが型安全に物足りないのは、失敗の情報がコンパイラに渡らないからです。具体的には2つの穴があります。1つはcatchで受け取る値の型、もう1つは関数のシグネチャです。
strictな設定(useUnknownInCatchVariables が有効な環境)では、catchの引数はunknown型になります。何が投げられるか静的には分からないため、安全側に倒した結果です。そのため、受け取った値のプロパティにそのままアクセスすると型エラーになります。
function parseConfig(raw: string): unknown {
return JSON.parse(raw);
}
try {
parseConfig("{ broken json");
} catch (e) {
e.message; // 例:TS18046 'e' is of type 'unknown'.(useUnknownInCatchVariables=true 前提。TypeScriptバージョンにより文言が異なる場合あり)
}エラーを使うにはe instanceof Errorなどで自分で絞り込む必要があり、雑に扱うとエラー情報を失いやすくなります。
もう1つの穴が関数の型に失敗が表れないことです。次の関数は内部でthrowしうるのに、戻り値の型はUserとしか言いません。
function findUser(id: string): User {
const user = db.get(id);
if (!user) throw new Error("not found"); // 失敗は型に出ない
return user;
}呼び出し側は型だけ見ても「失敗するかもしれない」と気づけず、try-catchで囲み忘れてもコンパイラは何も警告しません。例外は呼び出し階層をすり抜けて伝播するため、どこで握り潰されたか、あるいはどこにも捕まらず落ちたのかが追いにくくなります。
Result型とは|失敗を「値」で返す型

Result型とは、処理結果を「成功(Success)」と「失敗(Failure)」のユニオンで表す型です。失敗を例外として投げずに戻り値へ載せるので、関数のシグネチャに失敗の可能性がそのまま現れます。
type Success<T> = { ok: true; value: T };
type Failure<E> = { ok: false; error: E };
type Result<T, E> = Success<T> | Failure<E>;戻り値がResult<User, NotFoundError>なら、呼び出し側は型を見ただけで「失敗しうる」「失敗の中身はNotFoundErrorだ」と分かります。失敗が型システムの上に乗るのがtry-catchとの決定的な違いです。
RustのResult、ScalaやSwiftの同種の型は言語や標準ライブラリの機能として用意されていますが、TypeScriptには組み込みのResult型がありません。そのため、自前で型を定義するか、ライブラリを使うことになります。関数型の文脈では成功/失敗を表す型をEither(左=失敗・右=成功)と呼びますが、ここで使うResultはEitherの役割を「失敗」と「成功」に固定したものと考えれば十分で、本質は同じ判別可能ユニオンです。
判別可能ユニオンで型が絞り込まれる仕組み
Resultを分岐すると成功値とエラーが安全に取り出せるのは、okという共通の判別プロパティがあるからです。リテラル型true/falseを持つプロパティでユニオンを構成すると、その値を条件で確認した時点でTypeScriptがどちらの構成要素かを絞り込みます。これを判別可能ユニオン(discriminated union)と呼びます。
function show(res: Result<number, string>) {
if (res.ok) {
res.value.toFixed(2); // ここでは Success<number> に絞られ value が使える
} else {
res.error.toUpperCase(); // ここでは Failure<string> に絞られ error が使える
}
}if (res.ok) の中で res.error に触ろうとすると、その分岐にはerrorが存在しないため型エラーになります。コンパイラが分岐ごとにアクセス可能なプロパティを限定するので、成功時に存在しないエラーを読む、といった取り違えが起きません。
この絞り込みについて、TypeScript公式は「共通のプロパティを持ち、それがリテラル型であるユニオン」を判別可能ユニオンと呼び、そのプロパティで型が狭まると説明しています。
“When every type in a union contains a common property with literal types, TypeScript considers that to be a discriminated union, and can narrow out the members of the union.”
(TypeScript Handbook「Narrowing」Discriminated unions)


自前で書く最小のResult型
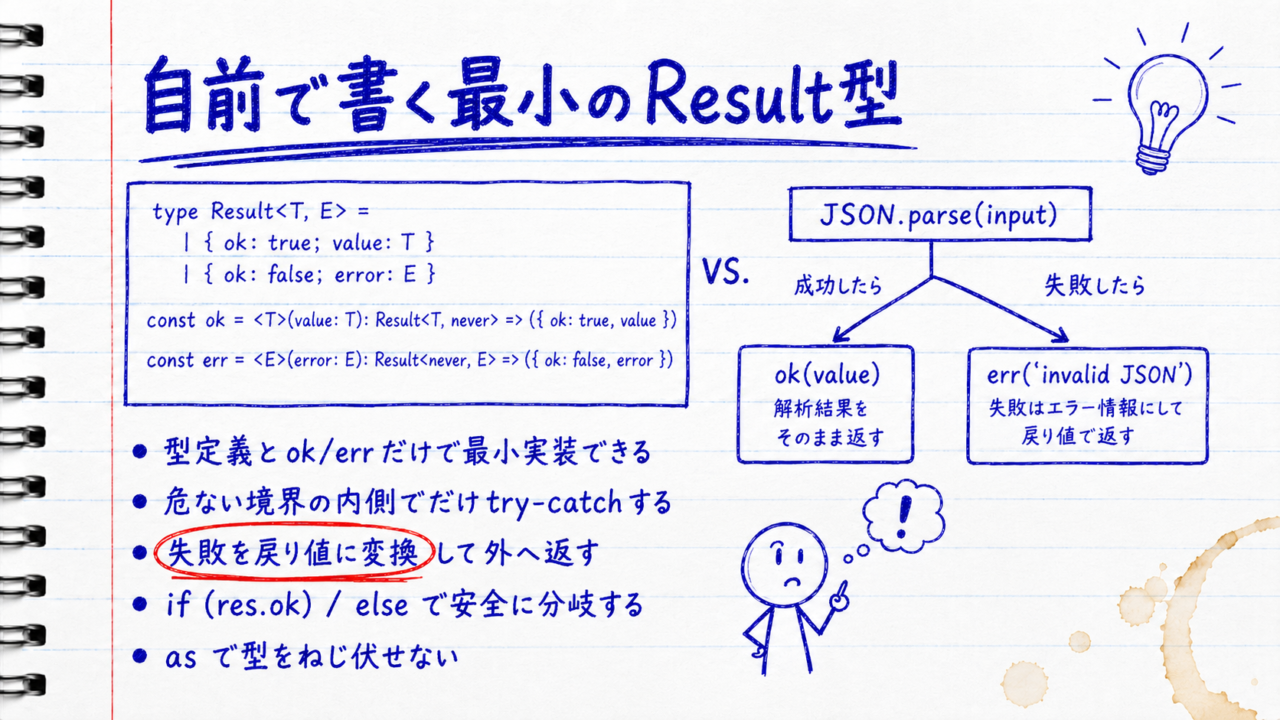
ライブラリを入れなくても、最小限の型定義とヘルパ2つでResult型は実装できます。先ほどのResult<T, E>に、成功と失敗を作る関数を足すだけです。
type Result<T, E> = { ok: true; value: T } | { ok: false; error: E };
const ok = <T>(value: T): Result<T, never> => ({ ok: true, value });
const err = <E>(error: E): Result<never, E> => ({ ok: false, error });これをJSONのパースに使ってみます。try-catchで囲んでいた処理を、失敗を戻り値に変換する形に書き換えます。
function parseJson(raw: string): Result<unknown, string> {
try {
return ok(JSON.parse(raw));
} catch {
return err("invalid JSON");
}
}
function printResult(res: Result<unknown, string>) {
if (res.ok) {
console.log(res.value); // 成功時はこちら
} else {
console.log(res.error); // 失敗時はこちら
}
}
const okRes = parseJson('{ "id": 1 }');
printResult(okRes); // { id: 1 }
const errRes = parseJson("{ broken");
printResult(errRes); // invalid JSON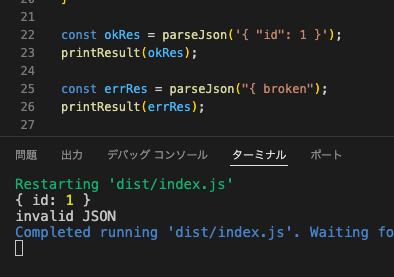
分岐するまでvalue/errorへの安全なアクセスはできないため、失敗処理を書き忘れにくくなります。ただし戻り値の無視までコンパイラ単体で防げるわけではないので、必要ならlintで補強します。try-catchをまったく使わないのではなく、危ない境界(ここではJSON.parse)の内側でだけ捕まえ、外へは値として返すのがコツです。
自前実装の限界
自前Result型は、処理を連鎖させたり非同期が絡んだりすると一気に書きづらくなります。原因は、毎回手動で成功/失敗を分岐しなければならないことです。
たとえば「JSONをparseし、その結果からidを取り出し、さらにIDでユーザーを引く」と段階を重ねると、各段でif (!res.ok) return resが並びます。
function pipeline(raw: string): Result<User, string> {
const parsed = parseJson(raw);
if (!parsed.ok) return parsed; // 定型の失敗チェック1
const id = extractId(parsed.value);
if (!id.ok) return id; // 定型の失敗チェック2
return findUser(id.value); // ようやく本処理
}段が増えるほど分岐の定型文が膨らみ、肝心の処理が埋もれます。さらにPromiseとResultを組み合わせると、Result<Promise<...>>なのかPromise<Result<...>>なのかで合成が煩雑になり、awaitと分岐が入り乱れます。この定型文を畳み込み、非同期も自然に扱う仕組みを提供するのがライブラリです。
neverthrowで実務的に書く
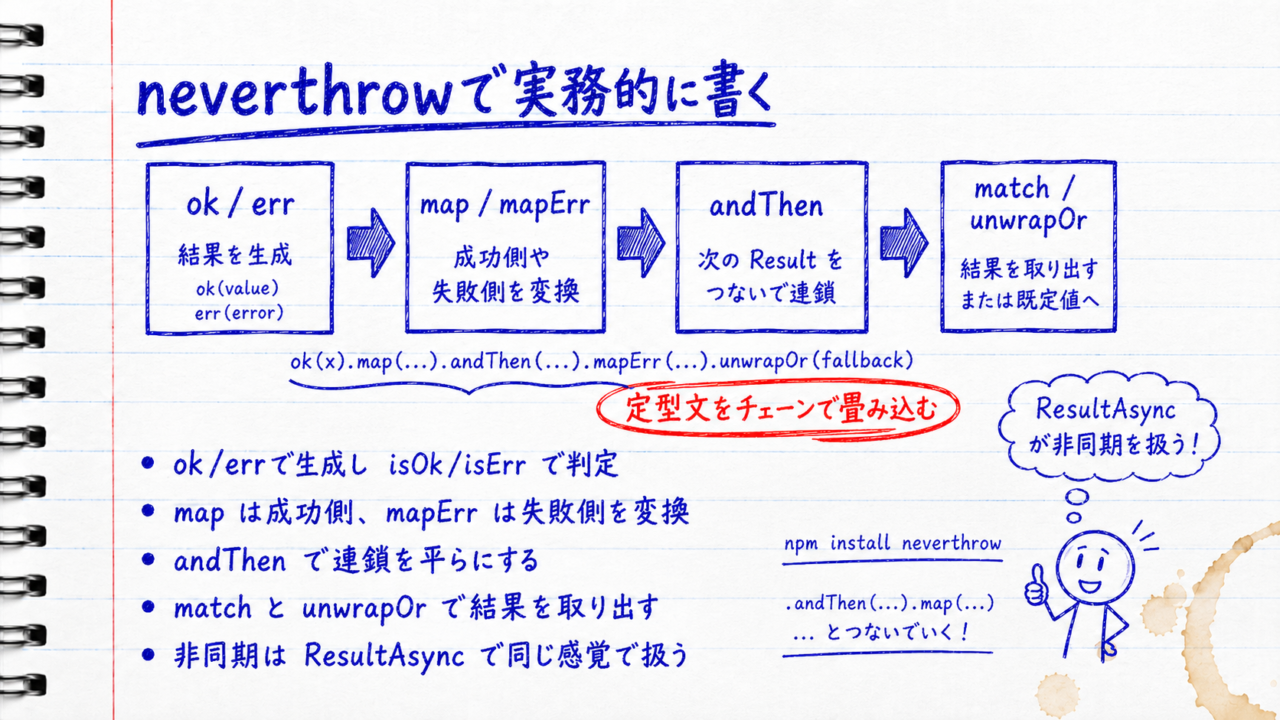
neverthrow(公式リポジトリ)を使うと、自前実装で膨らんだ分岐の定型文がメソッドチェーンに置き換わります。Result型と、その値を変換・連鎖させるメソッド群が用意されているのが要点です。APIの一覧や最新の仕様は公式READMEで確認できます。
npm install neverthrowokとerrで生成し、isOkで判定する
生成はok/err、判定はisOk/isErrで行います。成功ならisOk()がtrue・isErr()がfalse、失敗ならその逆になります。
import { ok, err, Result } from "neverthrow";
function parseJson(raw: string): Result<unknown, string> {
try {
return ok(JSON.parse(raw));
} catch {
return err("invalid JSON");
}
}
const res = parseJson('{ "id": 1 }');
console.log(res.isOk()); // true
console.log(res.isErr()); // false
const bad = parseJson("{ broken");
console.log(bad.isOk()); // false
console.log(bad.isErr()); // true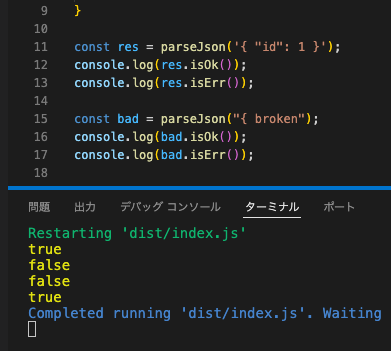
mapとmapErrで値を変換する
成功か失敗かを判定できたら、次はResultの中身をifで開かずに加工する段階です。中身を取り出さずに変換するためのメソッドがmapとmapErrで、成功側の値を変換するのがmap、失敗側のエラーを変換するのがmapErrです。mapは成功時だけ関数が走り、失敗のときは何もせずそのまま素通りします。
// 成功のときは map の関数が走る
const doubled = ok<number, string>(21).map((n) => n * 2);
console.log(doubled._unsafeUnwrap()); // 42(確認用に中身を直接取り出す)
// 失敗のときは map の関数は呼ばれず素通りする
const failed = err<number, string>("no id").map((n) => n * 2);
console.log(failed.isErr()); // true(map は実行されない)
// エラー側を変換したいときは mapErr を使う
const labeled = err<number, string>("no id").mapErr((e) => `error: ${e}`);
console.log(labeled._unsafeUnwrapErr()); // error: no id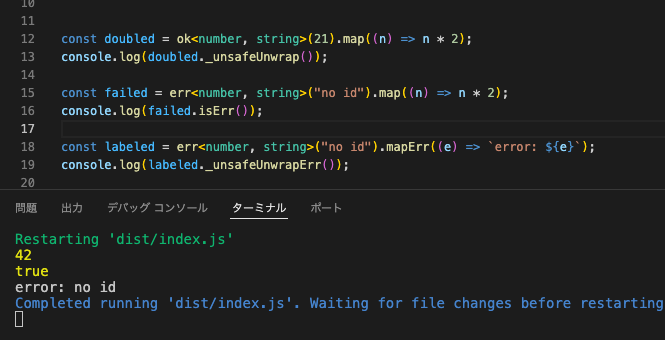
andThenで連鎖を平らにする
そして自前実装で辛かった連鎖は、andThenでネストを増やさずに書けます。andThenは「成功なら次のResultを返す関数へ進み、失敗ならそこで打ち切る」メソッドで、if (!res.ok) return resの繰り返しを畳み込みます。
const extractId = (v: unknown): Result<number, string> =>
typeof v === "object" && v !== null && "id" in v
? ok(Number((v as { id: unknown }).id))
: err("no id");
const result = parseJson('{ "id": 1 }')
.andThen(extractId)
.map((id) => id + 100);
console.log(result._unsafeUnwrap()); // 101(parse→id抽出→+100 が一気に流れた結果)
// 途中で失敗すると後続の andThen / map は走らず、最初のエラーで打ち切られる
const failure = parseJson("{ broken")
.andThen(extractId)
.map((id) => id + 100);
console.log(failure._unsafeUnwrapErr()); // invalid JSON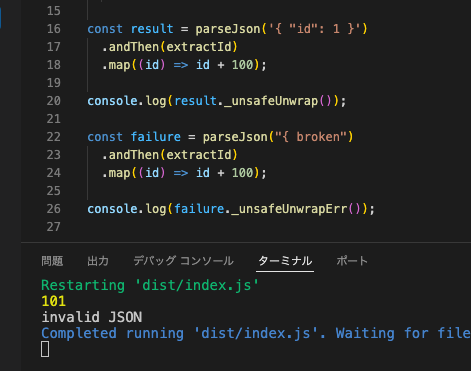
matchとunwrapOrで結果を取り出す
チェーンの最後は、Resultから中身を取り出して普通の値に戻す段階です。取り出しにはmatchとunwrapOrがよく使われます。
matchは成功用と失敗用の2つの関数を受け取り、成功なら第1引数の関数に成功値が、失敗なら第2引数の関数にエラーが渡されます。ifで開かなくても両方の分岐を1回で書けるのが利点です。下のコードでは、成功したresult(中身は101)は第1引数が走って成功: 101に、失敗したparseJson("{ broken")は第2引数が走って失敗: invalid JSONになります。
一方unwrapOrは「成功ならその中身、失敗なら渡した既定値」を返すメソッドです。成功したresultはそのまま101を、失敗したparseJson("{ broken")は既定値の-1を返します。失敗の中身を使わず既定値で流したい場面で手軽に使えます。
// match:成功なら第1引数、失敗なら第2引数の関数が走る
console.log(
result.match(
(value) => `成功: ${value}`,
(error) => `失敗: ${error}`,
),
); // 成功: 101
console.log(
parseJson("{ broken").match(
(value) => `成功: ${JSON.stringify(value)}`,
(error) => `失敗: ${error}`,
),
); // 失敗: invalid JSON
// unwrapOr:成功なら中身、失敗なら既定値を返す
console.log(result.unwrapOr(-1)); // 101(成功なので中身)
console.log(parseJson("{ broken").unwrapOr(-1)); // -1(失敗なので既定値)公式READMEでも、同期のResultに対する基本操作としてmap・mapErr・andThen・match・unwrapOrが「Synchronous API (Result)」として整理されています(neverthrow README「Synchronous API (Result)」)。なおsafeTryのような一部APIはバージョンによって提供状況や挙動が異なる場合があるため、利用前に手元のバージョンで確認してください。
非同期エラーをResultAsyncで扱う
Promiseが絡む処理は、ResultAsyncでラップすると同期のResultと同じ感覚で連鎖できます。awaitすると通常のResultが取り出せます。
既存のPromiseはfromPromiseで、throwしうる同期関数はfromThrowableでResultに包めます。fromPromiseの第2引数で、catchしたunknownを自分のエラー型へ変換します。
import { ResultAsync, fromThrowable } from "neverthrow";
// throwする関数をResultを返す関数に変換
const safeParse = fromThrowable(
(raw: string) => JSON.parse(raw) as unknown,
() => "invalid JSON",
);
// 既存のPromise(fetch等)をResultAsyncに変換
const fetchUser = (id: string): ResultAsync<Response, string> =>
ResultAsync.fromPromise(fetch(`https://jsonplaceholder.typicode.com/users/${id}`), () => "network error");
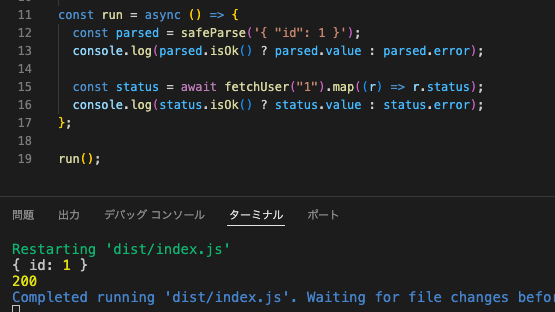
const run = async () => {
// 同期の throw を包んだ safeParse は Result を返す(await 不要)
const parsed = safeParse('{ "id": 1 }');
console.log(parsed.isOk() ? parsed.value : parsed.error); // { id: 1 }
// 非同期の fetch は ResultAsync。await すると通常の Result になる
const status = await fetchUser("1").map((r) => r.status);
console.log(status.isOk() ? status.value : status.error); // 200(fetch が返す HTTP ステータスコード)
};
mapやandThenはResultAsyncでもそのまま使え、同期と非同期で書き味が揃います。公式READMEでは、既存Promiseの変換はResultAsync.fromPromise、Promiseを返す関数のラップはResultAsync.fromThrowableとしてAsynchronous APIに整理されています。同期関数を包むトップレベルfromThrowableはUtilities(Result.fromThrowableのexport)です。
Result型を導入する場面と使い分けの判断軸
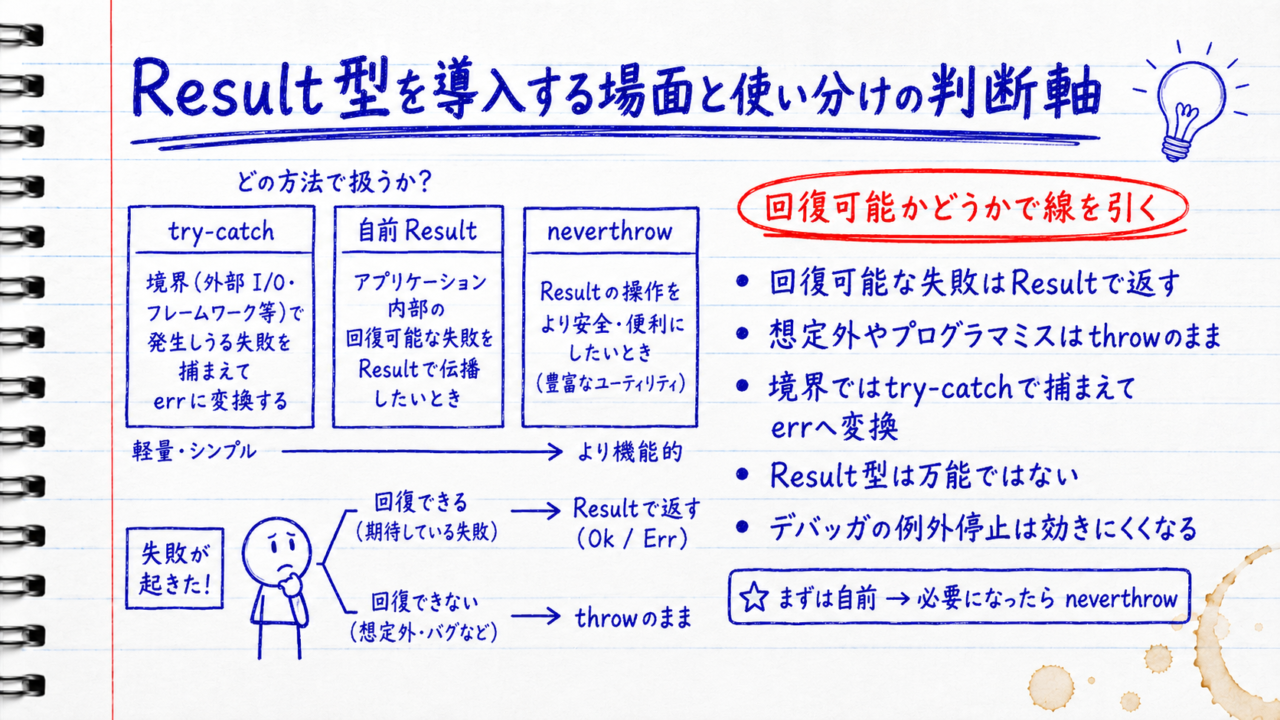
Result型をいつ使うかは「そのエラーが回復可能かどうか」で線を引くのが実用的です。呼び出し側がその場で対処できる失敗(入力不正、見つからない、通信失敗など)はResultで返し、プログラマのミスや想定外(nullのはずがないものがnull、到達不能なはずのコードなど)はthrowのままにします。後者までResult化すると、本来クラッシュさせて気づくべきバグを静かに値として運んでしまいます。
3つの手法の性格を並べると、選択の基準が見えてきます。
| 観点 | try-catch | 自前Result | neverthrow |
|---|---|---|---|
| 型安全(失敗が型に出る) | 出ない(catchはunknown) |
出る | 出る |
| 記述量 | 少ない(が握り潰しやすい) | 連鎖で定型文が増える | チェーンで簡潔 |
| 学習コスト | 低い | 低い | メソッド群の習得が必要 |
| デバッガの例外機能との相性 | 良い(例外ブレークが効く) | 例外を投げないため効きにくい | 同じく効きにくい |
| 非同期対応 | async/awaitで自然 | 合成が煩雑 | ResultAsyncで一貫 |
ここで見落とせないのが、Result型は万能ではないという点です。失敗を例外として投げないため、デバッガの「例外発生時に停止」が効きにくく、失敗箇所をブレークで捕まえる調査がしづらくなります。さらに、ライブラリ内部やランタイムは依然として例外を投げるので、try-catchから完全に逃れることはできません。境界では結局catchしてerrに変換する必要があります。
判断の流れはシンプルにできます。
- そのエラーは呼び出し側が回復・分岐できるか
できるならResultで返す - プログラマのミス・到達不能・回復不能な異常か
throwのまま落とす - 例外をResultに変えたい境界か
try-catchで捕まえてerrへ変換する
小さく自前必要になったらneverthrow
最初の一歩は、型2行とok/errの自前実装から始めるのが現実的です。連鎖が浅く非同期もほとんど絡まないうちは、ライブラリを足すより自前のほうが依存も学習コストも軽く、Result型の原理も身につきます。
ライブラリへ切り替える目安は、定型文の増加です。
if (!res.ok) return resが何段も並び始めた
andThenで畳み込みたくなる頃合い- Promiseと組み合わせる処理が増えてきた
ResultAsyncで一貫させたくなる - 複数人で書き、エラー変換の流儀を揃えたい
メソッドが共通言語になる
つまり「自前で原理を掴み、痛みが出たらneverthrowへ」という段階的な移行が、過剰投資も学習負債も避けられる落としどころです。
【付録】さらに学びを深めるためのリソース
さらにTypescriptの学習を進めたい方のために、いくつかのリソースを紹介します。
これらのリソースを活用することで、TypeScriptの型システムについてより深い知識を得ることができるでしょう。
おすすめの書籍
ゼロからわかる TypeScript入門

技術評論社から出版されている「ゼロからわかる TypeScript入門」は、プログラミング初心者や本職プログラマーではない方を主な対象にした入門書です。
変数・条件分岐・ループといった基本から、クラスやインターフェース、モジュールまで段階的に学べる構成になっています。最終章ではWeb APIとJSONを使った非同期Webアプリの作成も体験できるので、「実際に動くものを作る」ところまで到達できます。
プロを目指す人のためのTypeScript入門

技術評論社の「プロを目指す人のためのTypeScript入門 安全なコードの書き方から高度な型の使い方まで」、通称 ブルーベリー本 です。
JavaScriptの仕様とTypeScript独自の機能を両方押さえつつ、リテラル型・ユニオン型・keyof型・ジェネリクスなど、高度な型表現まで踏み込んで解説しています。TypeScriptの型システムの表現力を本格的に学べる一冊です。
オンラインで参照できる公式ドキュメント
TypeScript公式ハンドブック
https://www.typescriptlang.org/docs/
TypeScriptの公式ドキュメントです。
intersection型を含む、すべての型システムの機能について詳細な説明があります。
TypeScript Deep Dive
https://basarat.gitbook.io/typescript/
TypeScriptの深い部分まで掘り下げて解説しているオンラインブックです。
無料で読むことができ、intersection型についても詳しく説明されています。
TypeScriptの学習は終わりがありません。
新しい機能が常に追加され、より良い書き方が発見されています。
継続的に学習を続けることで、より良いTypeScriptプログラマーになれるはずです。
まとめ – 失敗を型に乗せて使い分ける

この記事の要点をまとめます。
- Result型は失敗を例外でなく「値」で返す発想で、try-catchの型の弱点(catchが
unknown・失敗がシグネチャに出ない)を補う ok: true/falseの判別可能ユニオンで、分岐すると成功値とエラーが安全に取り出せる- まずは型2行とok/errの自前実装で原理を掴み、連鎖や非同期が増えたらneverthrowの
map/andThen/matchへ移す - 全部をResult化しない。回復可能なエラーはResult、回復不可能・想定外はthrowで住み分け、デバッガ親和性の低下も踏まえて中立に判断する
失敗をどう表現するかは設計の選択です。Result型という選択肢を手の内に入れておけば、try-catchのままで十分な場面と、型で守りたい場面を切り分けて書けるようになります。
※本記事の本文案はAIを活用して作成していますが、記載している内容およびコードは筆者が実際に調査、検証・実行し、内容の正確性を確認した上で公開しています。











